Chemodiversity
A short overview of this project
Theoretic Biology Group
Bielefeld University
Bielefeld University
Defining Chemistry
- First of all we define the chemistry of our environment, so we know all possible interactions and can manipulate them at will.
- We differentiate between
SubstrateandProducts:Substratecan just be used (i.e. real substrates if the whole metabolism should be simulated,PPM[1] in our simplified case)Productsare nodes in our chemistry environment.
In Code:
data Compound = Substrate Nutrient| Produced Component| GenericCompound Int
Usage in the current Model
- The Model used for evaluation just has one
Substrate:
PPMwith a fixed Amount to account for effects of sucking primary-metabolism-products out of the primary metabolic cycle - This is used to simulate i.e. worse growth, fertility and other things affecting the fitness of a plant.
- We are not using named Compounds, but restrict to generic
Compound 1,Compound 2… - Not done, but worth exploring:
- Take a “real-world” snapshot of Nutrients and Compounds and recreate them
- See if the simulation follows the real world
Defining a Metabolism
- We define
Enzymes as- having a recipe for a chemical reaction
- are reversible
- may have dependencies on catalysts to be present
- may have higher dominance over other enzymes with the same reaction
- Input can be
Substrateand/orProducts - Outputs can only be
Products - \(\Rightarrow\) This makes them to Edges in a graph combining the chemical compounds
Usage in the current Model
Enzymes all- only map
1input to1Output with a production rate of1perEnzyme
(i.e.-1 Compound 2 -> +1 Compound 5) - are equally dominant
- need no catalysts
- only map
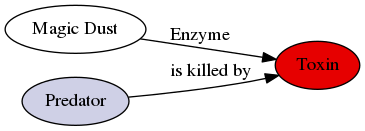
Defining Predators
Predators consist of- a list of
Compounds that can kill them - a fitness impact (\([0..1]\)) as the probability of killing the plant
- an expected number of attacks per generation
- a probability (\([0..1]\)) of appearing in a single generation
- a list of
Predatorneed not necessary be biologically motivated- i.e. rare, nearly devastating attacks (floods, droughts, …) with realistic probabilities
Example Environment
- The complete environment now consists of
Compounds:
![]()
Enzymes:
![]()
Predators:
![]()

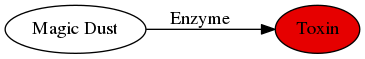
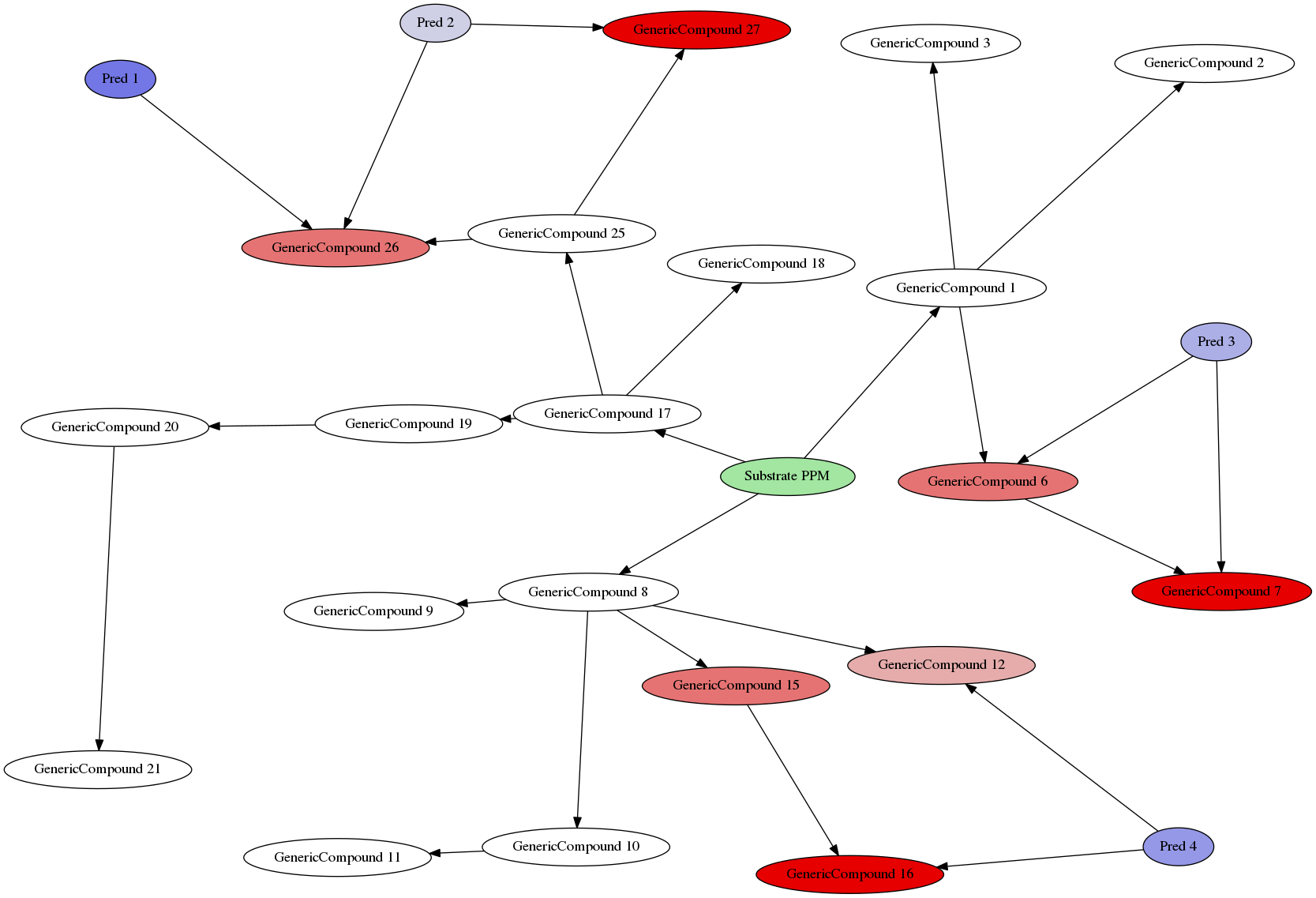
Additional rules:
- Every “subtree” from the marked
PPMis treated as a separate species (fungi, animals, …)
\(\Rightarrow\) Every predator can only be affected by toxins in the same part of the tree - Trees can be automatically generated in a decent manner to search for environmens where specific effects may arise
Effect of Predator-Behavior onto chemodiversity

Effect of static enzyme cost

Effect of static enzyme cost (cont.)

Effect of static enzyme cost (cont.)

Effect of nutrient-impact

Effect of nutrient-impact (cont.)

Effect of nutrient-impact (cont.)
